讓我們正式進入瀏覽器內部運作的議題。
前情提要
HTML5 的 Spec 裡面,對於建構 DOM 的過程有非常詳細的指示,HTML5 之前的版本都是由各家瀏覽器自己決定如何解析 HTML Document ,HTML5 的出現解決了這樣混亂的情況。此篇文章講解的是 HTML5 規範的流程。
當瀏覽器發送 Request 向 Server 索取頁面時,Server 便會將 HTML Document 傳給瀏覽器,那麼瀏覽器接收到 Server 的 Response 之後,它會做什麼事情呢?
首先我們要了解,計算機的世界裡資料都是以二進位的形式儲存,因此起初瀏覽器接收到的 Response 是由一個 byte 、一個 byte 所構成的,為了正確解析,瀏覽器做的第一件事就是將這些 bytes 按照特定編碼(如 UTF-8)轉換成一個一個字元。
按照特定編碼轉換成一個一個字元後,瀏覽器就會開始進行 tokenizing 的動作,將 strings 轉成不同的 token ,我們以下面這份簡單的 HTML Document 為例:
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<link href="style.css" rel="stylesheet">
<p>Hello!</p>
<div><img src="test.jpg"></div>
在 HTML Spec 裡都有定義每個 token 的意義以及規則,被包在 angle brackets 裡面的文字為 tag 。
Tokenization 的演算法很複雜,此演算法以 state machine 的方式表示。每一個 state 都會消耗 input stream 中一至多個字元,並且會根據這些字元更新下一個 state。
初始狀態(initial state)為「Data State」,遇到「<」這個字元,就會將狀態改變為「Tag Open Sate」,接著 consume 英文字母 a-z ,便會觸發「Start Tag Token」的創建,而改變成「Tag Name State」。遇到「>」這個字元後,當前的 token 就會被排出,返回至「Data State」,繼續往下重複上述動作。
最後結果用圖表示的話就是這樣:
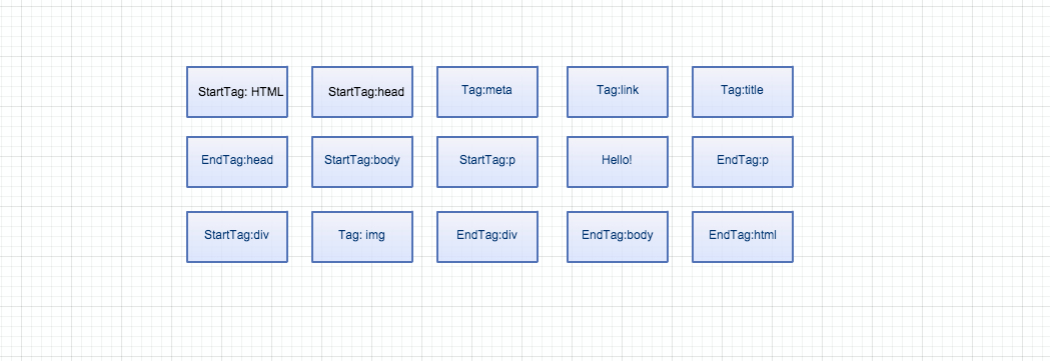
Tokenizing 這個階段結束後,瀏覽器就會開始將這些 Token 轉換成 node object , node object 之間有關係(relationship)存在,這個關係是透過 Start Tag 以及 End Tag 來辨識的。(可以看上面的 token 圖)以這裡的 tag 為例,因為它在 Start Tag 底下,因此 為 的 child。
在 裡面我們可以看到它有三個 child ,分別為 <meta> 、 <link> 以及 <title> ,而 裡面有 <p> 跟 <div> 兩個 child , <div> 裡面有 <img> 。
把每一個 token 轉換成 node object 之後,就是所謂的 DOM(Document Object Model),如下圖:

如果有注意就會發現我在 img 這個 node 的旁邊特別標注它的 src 屬性,實際上 DOM 就是整份 HTML Document 的表現,因此每個 node object 都會包含它特有的屬性以及內容,例如 <img> 的 src 屬性。

